

This is the start of a new series we're doing about MongoDB. We are going to take you through the ins and outs of using a NoSQl to store your data. MongoDB is one of the most popular DBMS out there and is the industry leading NoSQL database. MongoDB's popularity stems from its speed, ease of development, and flexibility. Instead of normalizing your data into a series of related tables, Mongo allows you to store all the relevant information into a single schemaless document. This not only makes writing queries faster but depending on how you set up your database this makes your queries execute faster too.
How Data is Stored
MongoDB allows you to store your data in a document similar to JSON or dictionaries in Python, documents in Mongo are a data structure made up of Key Value pairs Documents can be thought of as rows in a database, and documents are stored in a Collection, which would be similar to tables in a relational database. If you had a collection of movies and their critic scores a document in that collection might look something like this:
{
"_id": 1,
"title": "Jurassic Park",
"director": "Steven Spielberg",
"releaseData": "1993-06-11",
"criticScores": [
{
"source": "IMDB",
"score": 81
},
{
"source": "Rotten Tomatoes",
"score": 92
}
]
}
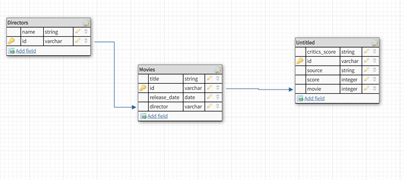
In the document above "title" is a key in the document and "Jurassic Park" is the associated value. The key "criticScores" has an array of documents stored as its value. Documents allow you to embed other documents as values. In the example above, critics score is an array of documents. If you were to query this collection for movies with the title "Jurassic Park" this entire document would be returned. In a relational database, you would have this information normalized across several tables. The same information in a relational database might be split out like similar to this schema diagram.
Queries
MongoDB is a NoSQL database, which means, you don't need to know SQL. If we wanted to query our movies collection for all Steven Spielberg movies we would write a query like this:
db.movies.find({
director: "Steven Spielberg",
});
Which would return a list of documents whose "director" field is equal to "Steven Spielberg". With the one short query your application has all the stored in the document available to it. Leaving you more time to work on what to do with the information instead of how you are going to get the information.
[
{
"_id": 1,
"title": "Jurassic Park",
"director": "Steven Spielberg",
"releaseData": "1993-05-11",
"criticScores": [
{
"source": "IMDB",
"score": 81
},
{
"source": "Rotten Tomatoes",
"score": 92
}
]
},
{
"_id": 2,
"title": "Jaws",
"director": "Steven Spielberg",
"releaseData": "1975-06-20",
"criticScores": [
{
"source": "IMDB",
"score": 80
},
{
"source": "Rotten Tomatoes",
"score": 97
}
]
},
{
"_id": 3,
"title": "E.T. the Extra-Terrestrial",
"director": "Steven Spielberg",
"releaseData": "1982-06-11",
"criticScores": [
{
"source": "IMDB",
"score": 79
},
{
"source": "Rotten Tomatoes",
"score": 98
}
]
}
]
How do we use MongoDB?
We use Mongo as the database for our Petro.ai engine. The flexibility of the document model is what allows us to create a database that could handle the variation in our customers data. As long as they at minimum can provide data for the fields that our application requires, they can store additional data inside of our model.
Coming up
We will continue to explore the document model, show you how to perform CRUD operations, and talk about how to get the most out of MongoDB. If you are interested in learning MongoDB you should continue following this series, and you should also check out the resources that MongoDB provides. They have great documentation and online courses.

